Database Replication
Database Replication là gì?
Hãy tưởng tượng bạn đang điều hành một quán cà phê nhỏ. Ban đầu, quán chỉ có một quầy pha chế. Khi khách hàng tăng vọt, nhân viên làm việc không kịp và nếu quầy này gặp sự cố thì toàn bộ quán sẽ phải dừng hoạt động và rồi khách hàng sẽ bỏ đi hết.
Để khắc phục thì bạn quyết định đầu tư thêm vài quầy pha chế phụ có cách vận hành và menu giống hệt quầy chính. Giờ đây, khách có thể được phục vụ nhanh hơn ở nhiều quầy và nếu một quầy gặp vấn đề, các quầy khác vẫn hoạt động bình thường.
Tương tự trong thế giới công nghệ, database replication là quá trình tạo các bản sao dữ liệu từ một máy chủ chính (Leader/Primary) sang nhiều máy chủ phụ (Followers/Replicas). Điều này giúp hệ thống đạt được các lợi ích chính sau:
- Tính sẵn sàng cao (High Availability): Khi máy chủ chính gặp sự cố, hệ thống tự động chuyển sang máy chủ phụ mà không làm gián đoạn dịch vụ.
- Cân bằng tải (Load Balancing): Các truy vấn đọc (read) có thể được phân tán ra nhiều máy chủ phụ, giảm tải cho máy chủ chính, giúp hệ thống xử lý nhiều request hơn mà không bị nghẽn.
- An toàn dữ liệu (Data Safety): Dữ liệu được lưu trữ ở nhiều nơi, thường ở các vị trí địa lý khác nhau, giúp giảm rủi ro mất mát do hỏng hóc phần cứng, thiên tai hoặc lỗi hệ thống. Ngoài ra, replication còn hỗ trợ sao lưu dữ liệu tự động và phục hồi nhanh chóng.
Các mô hình Database Replication phổ biến
Có ba mô hình chính là Leader-Follower (hay Master-Slave), Multi-Leader (Multi-Master) và Leaderless. Mỗi mô hình có cách thức hoạt động, ưu nhược điểm riêng, phù hợp với các kịch bản khác nhau.
Leader-Follower Replication (còn gọi là Master-Slave Replication)
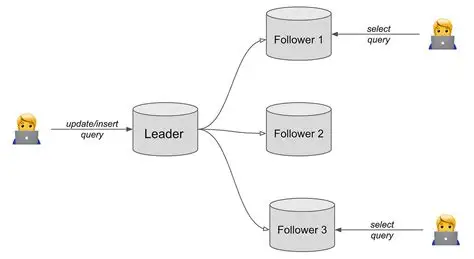
Đây là mô hình phổ biến nhất. Trong mô hình này:
- Một cơ sở dữ liệu được chỉ định làm Leader (còn gọi là Master/Primary). Đây là nơi duy nhất được thực hiện các thao tác ghi (INSERT/UPDATE/DELETE).
- Các cơ sở dữ liệu còn lại là Follower (còn gọi là Slave/Replica/Secondary). Chúng chỉ được phép thực hiện thao tác đọc (READ).
Mọi thay đổi dữ liệu đều diễn ra trên Leader trước. Sau đó, các thay đổi này được đồng bộ sang các Follower. Quá trình đồng bộ có thể diễn ra theo kiểu đồng bộ (synchronous) hoặc bất đồng bộ (asynchronous), tùy thuộc vào nhu cầu về tốc độ và độ an toàn dữ liệu:
- Đồng bộ (Synchronous Replication): Leader sẽ chờ xác nhận từ ít nhất một Follower (hoặc tất cả tùy vào cấu hình) trước khi thông báo cho client rằng thao tác ghi đã thành công. Ưu điểm là đảm bảo dữ liệu luôn cập nhật và nhất quán, giảm rủi ro mất mát nếu Leader gặp sự cố. Tuy nhiên, nhược điểm là chậm hơn vì phải chờ đợi, và hệ thống có thể bị treo nếu Follower chậm hoặc ngừng hoạt động.
- Bất đồng bộ (Asynchronous Replication): Leader ghi dữ liệu và xác nhận ngay với client rồi mới gửi thay đổi sang Follower sau. Cách này nhanh hơn, giúp hệ thống sẵn sàng cao, nhưng có thể dẫn đến độ trễ đồng bộ (replication lag), nghĩa là dữ liệu trên Follower chưa kịp cập nhật, dẫn đến việc đọc dữ liệu cũ. Ngoài ra, nếu Leader fail trước khi đồng bộ, có nguy cơ mất dữ liệu.
Vậy Leader đồng bộ dữ liệu với Follower bằng cách nào? Có các cơ chế chính sau:
- Statement-Based Replication: Leader ghi lại toàn bộ câu lệnh SQL và gửi chúng cho các Follower. Các follower sẽ thực thi lại các câu lệnh này. Phương pháp này đơn giản, dễ triển khai, nhưng dễ gặp vấn đề nếu câu lệnh phụ thuộc vào thời gian (ví dụ hàm NOW()) hoặc môi trường cụ thể của Leader, dẫn đến kết quả khác nhau trên Follower.
- Row-Based Replication: Thay vì gửi statement, Leader gửi trực tiếp các thay đổi trên từng hàng dữ liệu (như "hàng id=1, cột name thay từ 'A' sang 'B'"). Cách này tránh được vấn đề không deterministic của statement-based, nhưng có thể tốn nhiều tài nguyên hơn vì dữ liệu gửi đi chi tiết hơn.
- Write-Ahead Log (WAL) Shipping: Đây là cơ chế được ưa chuộng. Mọi thay đổi dữ liệu trên Leader trước tiên được ghi vào một tệp log nhị phân đặc biệt (gọi là Write-Ahead Log). Các follower liên tục sao chép và replay log này để áp dụng các thay đổi chính xác như trên Leader. WAL đảm bảo tính nhất quán và toàn vẹn dữ liệu rất cao, thường dùng trong các hệ thống như PostgreSQL.
Quá trình đồng bộ này không phải lúc nào cũng xảy ra tức thời, dẫn đến hiện tượng Replication Lag (độ trễ đồng bộ) - tình trạng dữ liệu vừa được ghi lên Leader nhưng chưa kịp cập nhật xuống Follower, nên khi đọc từ Follower, người dùng sẽ thấy dữ liệu cũ.
Mô hình này được áp dụng rộng rãi trong MySQL (với statement/row-based), PostgreSQL (WAL shipping).
Multi-Leader Replication (còn gọi là Multi-Master Replication)
Hãy tưởng tượng bạn mở thêm các chi nhánh cà phê ở các thành phố khác. Mỗi chi nhánh đều có quầy pha chế chính của riêng nhưng chúng cần đồng bộ menu, công thức và tồn kho để đảm bảo tính nhất quán toàn hệ thống.
Trong mô hình này, có nhiều hơn một database đóng vai trò Leader. Mỗi Leader đều có thể nhận cả thao tác write và read và dữ liệu sẽ được đồng bộ hai chiều giữa các Leader với nhau.
Mô hình này có một vấn đề là xung đột ghi (Write Conflict), ví dụ hai user sửa cùng một record trên hai Leader khác nhau. Để giải quyết, cần cơ chế conflict resolution như last write wins (dựa trên timestamp, nhưng có thể mất dữ liệu), version vectors, CRDTs (Conflict-free Replicated Data Types), hoặc merge thủ công.
Mô hình này phù hợp với các ứng dụng phân tán trên toàn cầu, nơi yêu cầu ghi có thể xảy ra ở nhiều trung tâm dữ liệu khác nhau.
Leaderless Replication
Hãy tưởng tượng một hệ thống mà khách hàng có thể đặt hàng ở bất kỳ quầy nào và nhân viên ở các quầy khác sẽ tự động cập nhật lại menu cho đồng bộ.
Ở mô hình này không có khái niệm Leader. Client gửi write đến nhiều node cùng lúc và hệ thống yêu cầu thành công trên một quorum (ví dụ: write thành công trên 3/5 node). Khi read, client đọc từ nhiều node và lấy phiên bản mới nhất dựa trên version number.
Các cơ sở dữ liệu NoSQL như Amazon DynamoDB và Apache Cassandra thường sử dụng mô hình này.
Tối ưu Replication Lag
Replication lag là khoảng thời gian mà dữ liệu mới ghi trên Leader chưa kịp cập nhật sang Follower, dẫn đến tình trạng đọc dữ liệu cũ hoặc không nhất quán tạm thời. Điều này thường xảy ra trong replication bất đồng bộ, nơi Leader không chờ Follower xác nhận trước khi commit.
Để giảm thiểu replication lag, bạn có thể áp dụng một số chiến lược sau.
Sử dụng Synchronous Replication
Thay vì cho phép Leader commit ngay lập tức (asynchronous), bạn có thể cấu hình để Leader chỉ commit sau khi nhận xác nhận từ ít nhất một hoặc tất cả Follower. Cách này loại bỏ hoàn toàn lag vì dữ liệu luôn được đồng bộ trước khi transaction hoàn tất.
Chuyển dữ liệu trực tiếp từ memory Leader sang Follower (Memory-based Streaming)
Thay vì dựa vào việc ghi log ra đĩa rồi ship file (WAL shipping truyền thống), bạn có thể stream các thay đổi trực tiếp từ bộ nhớ (memory) của Leader sang Follower. Điều này giảm thời gian chờ I/O và làm cho đồng bộ nhanh hơn, đặc biệt trong môi trường có băng thông cao.
Tối ưu hóa mạng và phần cứng
Đảm bảo kết nối mạng nhanh, sử dụng storage nhanh hơn như SSD thay vì HDD, và theo dõi bằng công cụ như iostat để tránh bottleneck ở đĩa. Ví dụ, đặt Follower ở cùng data center với Leader để giảm độ trễ.
Áp dụng Parallel Replication
Cho phép Follower apply thay đổi song song bằng nhiều thread, thay vì sequential. Trong MySQL hoặc MariaDB, kích hoạt parallel replication để xử lý tải cao hơn mà không tăng lag.
Giảm tải và tối ưu query
Chỉnh index cho table, fix slow write queries, và phân tải read sang Follower để Leader không bị overload. Ngoài ra, sử dụng compression cho WAL để giảm lượng dữ liệu truyền.
Database replication là một công cụ mạnh mẽ giúp xây dựng hệ thống dữ liệu bền vững, hiệu suất cao và sẵn sàng đối mặt với mọi sự cố. Việc chọn mô hình phù hợp phụ thuộc vào yêu cầu cụ thể của ứng dụng bạn. Hy vọng bài viết này giúp bạn nắm vững hơn về chủ đề này!
Bình luận
Gợi ý